
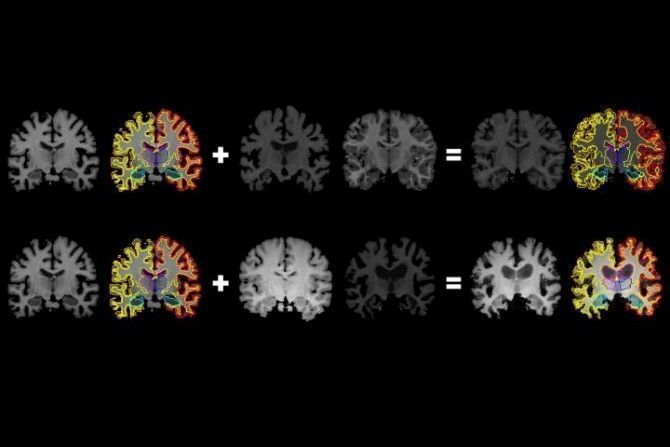
Los investigadores del MIT han ideado un método novedoso para recopilar más información de las imágenes utilizadas para entrenar modelos de aprendizaje automático, incluidos aquellos que pueden analizar exploraciones médicas para ayudar a diagnosticar y tratar afecciones cerebrales.

Una nueva área activa en medicina implica la capacitación de modelos de aprendizaje profundo para detectar patrones estructurales en escáneres cerebrales asociados con enfermedades y trastornos neurológicos, como la enfermedad de Alzheimer y la esclerosis múltiple. Pero recopilar los datos de entrenamiento es laborioso: todas las estructuras anatómicas en cada exploración deben estar delineadas por separado o etiquetadas a mano por expertos en neurología. Y, en algunos casos, como en el caso de enfermedades cerebrales raras en los niños, en primer lugar solo pueden estar disponibles algunas exploraciones.
En un artículo presentado en la reciente Conferencia sobre Visión por Computador y Reconocimiento de Patrones, los investigadores del MIT describen un sistema que utiliza un solo escaneo etiquetado, junto con escaneos no etiquetados, para sintetizar automáticamente un conjunto de datos masivo de distintos ejemplos de entrenamiento. El conjunto de datos se puede utilizar para entrenar mejor los modelos de aprendizaje automático para encontrar estructuras anatómicas en nuevos escaneos: cuanto más datos de entrenamiento, mejores sean esas predicciones.
El punto crucial del trabajo es la generación automática de datos para el proceso de «segmentación de imagen», que divide una imagen en regiones de píxeles que son más significativas y fáciles de analizar. Para hacerlo, el sistema utiliza una red neuronal convolucional (CNN), un modelo de aprendizaje automático que se ha convertido en una fuente inagotable de tareas de procesamiento de imágenes. La red analiza una gran cantidad de exploraciones sin etiquetas de diferentes pacientes y diferentes equipos para «aprender» las variaciones anatómicas, de brillo y de contraste. Luego, aplica una combinación aleatoria de esas variaciones aprendidas a un solo escaneo etiquetado para sintetizar nuevos escaneados que son realistas y están etiquetados con precisión. Estas exploraciones recién sintetizadas se incorporan a una CNN diferente que aprende a segmentar nuevas imágenes.
«Esperamos que esto haga que la segmentación de la imagen sea más accesible en situaciones realistas en las que no tiene muchos datos de capacitación», dice la primera autora Amy Zhao, estudiante graduada del Departamento de Ingeniería Eléctrica y Ciencias de la Computación (EECS) y Laboratorio de Informática e Inteligencia Artificial (CSAIL). «En nuestro enfoque, puede aprender a imitar las variaciones en escaneos sin etiqueta para sintetizar de manera inteligente un gran conjunto de datos para capacitar a su red».

















{kind=link}